TOC
- 一、Redis介绍
- 二、字符串类型(String)
- 三、哈希类型(hash)
- 四、列表(List)
- 五、集合(Set)
- 六、设置过期时间
- 七、事务(Transaction)
- 八、持久化(persistence)
一、Redis介绍
1. 简介
以下是官方文档的解释。
Redis 是一个使用 ANSI C 编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。
Redis 不是简单的 Key-Value 数据库,它还支持数据结构,例如
- 字符串
- 哈希
- 列表
- 集合
- 带范围查询的排序集合
- 位图
- 超日志
- 带有半径查询和流的地理空间索引
Redis具有内置的复制功能,解析执行 Lua 脚本,LRU 缓存控制,事务和不同级别的磁盘持久性,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。
2. 存储结构
在大多数编程语言中都有一种数据结构:字典,例如代码 dict["key"] = "value" 中:
dict是一个字典结构变量key是键名value是键值
在字典中我们可以获取或设置键名对应的键值,也可以删除一个键。
Redis 字典中的键值除了可以是字符串,还可以是其它数据类型。其中比较常见的有:
| 说明 | 类型 |
|---|---|
| 字符串 | String |
| 散列,是由与值相关联的字段组成的内容。字段和值都是字符串。类似于 JavaScript 中的对象结构。 | Hash |
| 列表,根据插入顺序排序的字符串元素的集合。它们基本上是链表。 | List |
| 未排序的字符串元素集合,集合中的数据是不重复的 | Set |
| 与 Sets 类似,但每个字符串元素都与一个称为分数的浮点值相关联。元素总是按它们的分数排序,因此与 Set 不同,可以检索一系列元素(例如,您可能会问:给我前 10 名或后 10 名) | ZSet |
3. 功能
Redis 虽然是作为数据库开发的,但是由于提供了丰富的功能,越来越多人将其用作缓存、队列系统等。
(1)作为缓存系统
Redis 可以为每个键设置生存时间,生存时间到期后会自动被删除。这一功能配合出色的性能让 Redis 可以作为缓存来使用。作为缓存系统,Redis 还可以限定数据占用的最大空间,在数据达到空间限制后可以按照一定的规则自动淘汰不需要的键。
(2)作为队列系统
除此之外,Redis 的列表类型键可以用来实现队列,并且支持阻塞式读取,可以很容易的实现一个高性能的优先级队列。
(3)“发布/订阅”功能
同时在更高层面上,Redis 还支持“发布/订阅”的消息模式,可以基于此构建聊天室等系统。
二、字符串类型(String)
1. 添加
- SETNX key value 当 key 不存在时设置 key 的值
- MSET key1 value1 key 2 value2 设置多个键值
2. 查询
- keys * 查看所有key
- GET key 查询该key
- GETRange key start end 返回 key 中字符串的子字符,start和 end 为字符索引
- STRLEN key 返回值的长度
- MGET key1 key2 … 获取一个或多个给定 key 的值
- EXISTS key 查询集合中是否有指定的key,可以查询多个key,返回值为存在的个数
- TYPE key 查询 key 的类型
3. 修改
- SET key value 设置键值
- GETSET key value 获取 key 并设置 key 的值
- APPEND key value 追加值到末尾
4. 删除
DEL key1 key2 ...:删除一个或多个key
5. 数字值
数字值在 Redis 中以字符串形式保存
- INCR key:将数字值+1
- INCRBY key increment:自定义增加的值
- DECR key:-1
- DECRBY key decrement:自定义减小的值
三、哈希类型(hash)
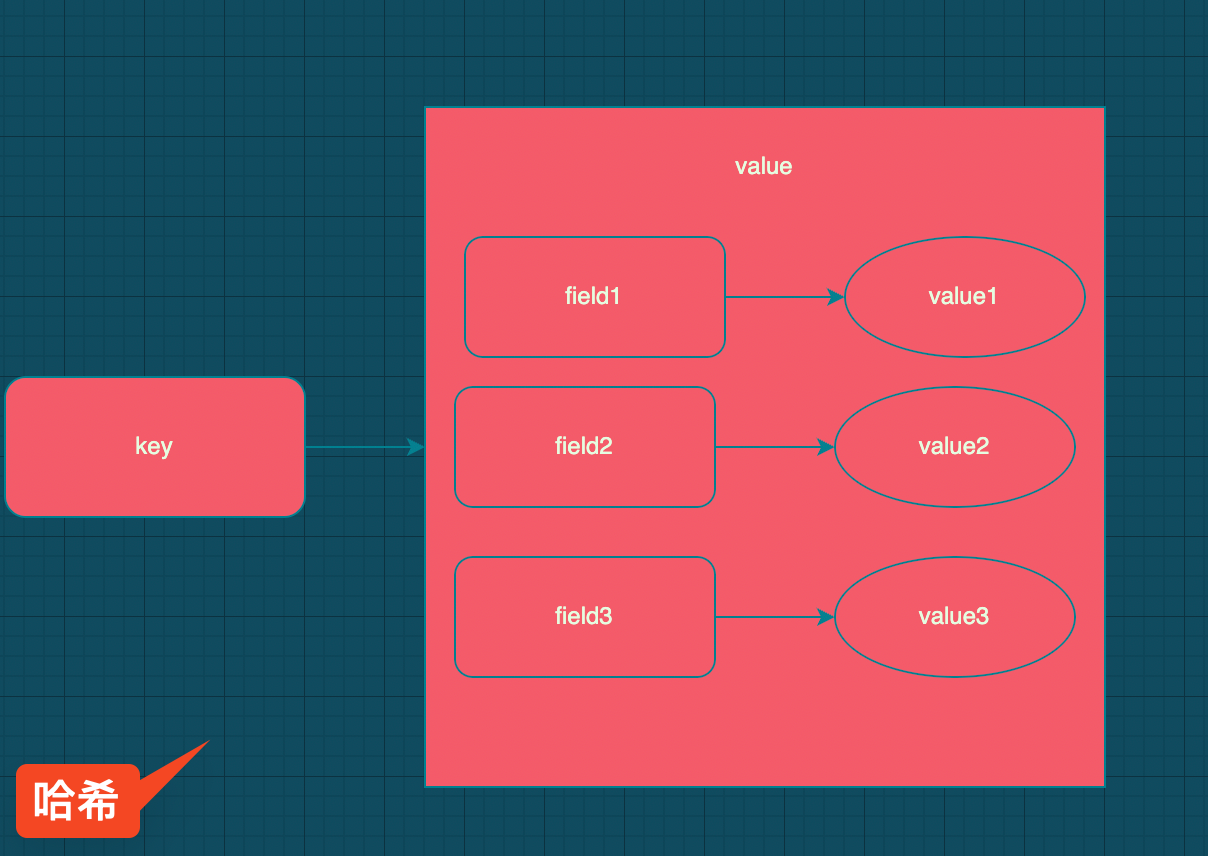
哈希(散列)类型也是一种字典结构,其储存了字段和字段值的映射,但字段值只能是字符串。
1. 添加
- HSET key field1 value1 field2 value2 …添加一个或多个字段与字段值
- HSETNX key field value field不存在时设置字段值value
2. 查询
- HKEYS key 获取 key 的所有字段值
- HLEN key 获取 key 中字段的数量
- HMGET key field1 field2… 获取 key 中多个字段值
- HGET key field 获取字段值
- HGETALL key 获取 key 中所有的字段及字段值
- HVALS key 获取 key 中所有字段值
3. 修改
- HSET key field value 与添加类似
- HINCRBY key field increment 为哈希表 key 中的指定字段的整数加上increment(正/负)的值
4. 删除
- HDEL key field1 field2… 删除一个或多个字段
- DEL key 删除该哈希表
四、列表(List)
列表内部使用双向链表实现,向列表两端添加元素时间复杂度为O(1),获取越接近两端的元素越快,缺点是通过索引获取较慢。
1. 添加
- LPUSH key element1 element2 .. 插入元素到列表头部
- RPUSH key element elament 插入元素到末尾
- LINSERT key BEFORE|AFTER pivot value 在列表中指定的元素前或者后插入元素
- LSET key index value 通过索引设置值
2. 查询
- LINDEX key index 通过索引获取列表中的元素
- LLEN key 获取列表长度
- LRANGE key start end 通过指定索引范围查询
3. 删除
- LPOP key 移除头部第一个元素
- RPOP key 移除末尾第一个元素
- LREM key count element 移除 count 个值为 element 的元素,如果count > 0从头开始遍历,小于 0 则从尾部遍历,等于 0 删除所有匹配元素
五、集合(Set)
集合中元素是唯一、无序的,与列表类型比较相似,区别为:
- 列表为有序,集合无序
- 列表数据可以重复,集合无重复元素
由于集合在 Redis 内部是使用值为空的散列表实现,所以对集合的插入、删除以及判断某个元素是否存在等的时间复杂度都是O(1)。
多个集合之间还可以进行并交差集运算。
1. 添加
SADD key member1 member2向集合添加一个或多个成员
2. 查询
- SMEMBERS key 返回集合中的所有成员,由于集合是无序的,所以与插入时的顺序会有所不同
- SCARD key 获取集合的成员数
- SISMERBER key member 判断元素是否存在,返回 1 位存在,0为不存在
- SRANDMEMBER key count 返回集合一个或多个随机数
3. 删除
- SREM key member1 member2 删除一个或多个成员
- SPOP key 移除并返回集合中的一个随机元素
- SMOVE source destination member 元素从一个集合移动到另一个集合
4. 集合间运算
- SDIFF key1 key2 返回第一个集合与第二个集合的差集,通俗说就是返回第一个集合中第二个集合中没有的元素。不同的顺序会有不同的差异, 比如 myset1 的值为”a”, “b”, “c”,myset2的值为”a”, 如果执行
SDIFF myset2 myset1会返回空,因为拿 myset2 与myset1进行比较,myset2中元素在 myset1 中都存在,所以没有差异,一旦拿 myset1 与myset2进行比较,则返回”b” “c” - SINTER key1 key 返回集合的交集
- SUNION key1 key2 返回集合的并集,会排除重复元素
- SDIFFSTORE destination key1 key2 返回给定集合的差集并存储在destination
- SINTERSTORE destination key1 key2 返回给定集合的交集并存储在destination
- SUNIONSTORE destination key1 key2 返回给定集合的并集并存储在destination
5. 使用场景
- 跟踪一些唯一性数据,比如访问网站的 ip 地址,每次访问记录用户ip,并能够保证 ip 不重复
- 充分利用 SET 聚合操作方便高效的特性,用于维护数据对象之间的关联关系,比如 A 产品购买者的用户 id 放入 SET1 中,B产品购买者的用户 id 放入 SET2 中,想知道哪些用户同时购买了这些产品,只需要取这两个集合的交集即可。
6. 有序集合
1. 介绍
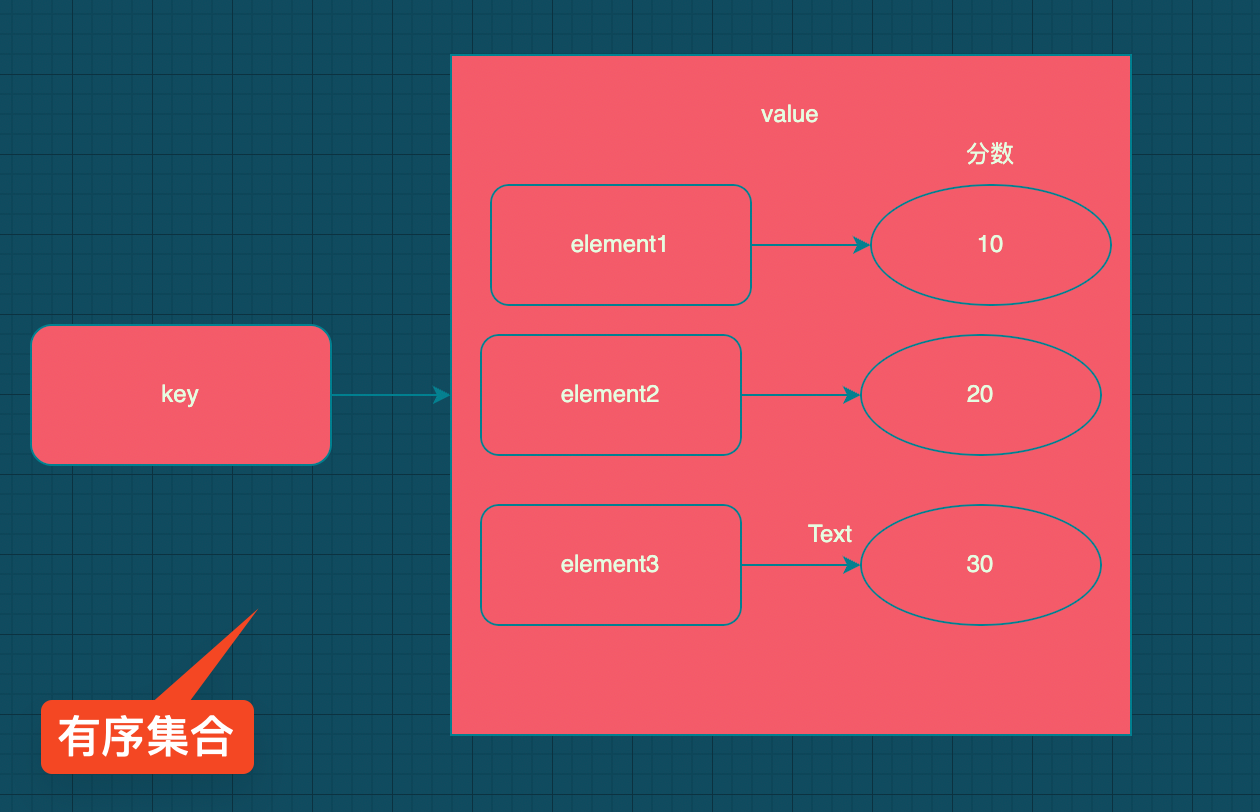
有序集合是一种类似于集合和哈希之间的混合数据类型,有序集合与集合相同之处是两者都是没有重复元素,但有序集合中每个元素关联了一个分数,这就是与哈希类似的地方,因为每个元素都映射到一个值。
有序集合在某些方面和列表类型有些相似,两者都是有序的,两者都可以获得某一范围的元素,列表通过链表实现,访问中间数据将会变慢 但有序集合内部使用的是哈希表实现,所以即使读取位于中间部分的数据速度也很快。列表也不能简单的调整某个元素的位置,但有序集合可以通过改变元素的分数来改变,有序集合结构也会消耗更多的内存。
2. 添加
ZADD key score1 member1 score2 member2:向有序集合添加一个或多个成员。
3. 查询
- ZRANGE key start stop WITHSCORES(可选,是否携带分数) 通过索引返回有序集合的成员,升序返回。
- ZREVRANGE key start stop WITHSCORES 降序返回
- ZRANGEBYSCORE key min max WITHSCORES 返回指定分数区间的成员
- ZRERANGESCORE key max min WITHSCORES 返回指定分数区间的成员
- ZRANK key memeber 返回有序集合指定成员的分数从小到大的排名
- ZRERANK key member 返回有序集指定成员的分数从大到小的排名
- ZCARD key 获取集合的成员数
- ZCOUNT key min max 获取指定分数区间的成员数
4. 修改
- ZADD key score1 member1 … 添加成员或更新分数
- ZINCRBY key increment member 对指定成员的分数加上增量increment
5. 删除
- ZREM key member1 … 删除一个或多个成员
- ZREMRANGBYRANK key start end 移除给定排名区间的所有成员
- ZREMRANGBYSCORE key min max 移除有序集合中给定的分数区间的所有成员
6. 有序集合间聚合运算
ZINTERSTORE destination numkeys key 将有序集合交集结果存入 destination 中
ZUNIONSTORE destination numkeys key 将并集存入 destination 中
六、设置过期时间
redis存储的缓存、验证码、限时优惠活动等,过了时间后需要进行清除,所以需要设置一个过期时间。
- EXPIRE key seconds 设置以秒为单位的过期时间
- PEXPIRE key milliseconds 以毫秒为单位
- TTL key 查看剩余时间(秒),返回数字-2代表已过期并清除,-1为未设置过期时间,>0则为剩余的秒数。
- PTTL key 返回毫秒
- PERSIST key 移除过期时间
需要注意的是,如果使用了SET/GETSET为键赋值,会清除掉过期时间,而只是键的值进行操作不会产生影响。
七、事务(Transaction)
1. 基础概念
关于事务最常见的例子就是银行转账,A 账户给 B 账户转账一个亿 (T1)。在这种交易的过程中,有几个问题值得思考:
- 如何同时保证上述交易中,A账户总金额减少一个亿,B账户总金额增加一个亿? Atomicity
- 如何在支持大量交易的同时,保证数据的合法性(没有钱凭空产生或消失) ? Consistency
- A账户如果同时在和 C 账户交易(T2),如何让这两笔交易互不影响? Isolation
- 如果交易完成时数据库突然崩溃,如何保证交易数据成功保存在数据库中? Durability
要保证交易正常可靠地进行,数据库就得解决上面的四个问题,这也就是事务诞生的背景,它能解决上面的四个问题,对应地,它拥有四大特性(ACID)。
(1)原子性(Atomicity): 事务要么全部完成,要么全部取消。 如果事务崩溃,状态回到事务之前(事务回滚)。
确保不管交易过程中发生了什么意外状况(服务器崩溃、网络中断等),A和 B 账户的金额变动要么同时成功,要么同时失败(保持原状)。
(2)一致性(Consistency): 只有合法的数据(依照关系约束和函数约束)才能写入数据库。
转账前和转账后的数据都要是正确的状态,如果 A 账户少了一亿而 B 账户没有增加,或者 A 账户未减少 B 账户却凭空增加了一亿都没有达到一致性。
(3)隔离性(Isolation): 如果 2 个事务 T1 和 T2 同时运行,事务 T1 和 T2 最终的结果是相同的,不管 T1和 T2 谁先结束。
如果 A 在转账 1 亿给B(T1),同时 C 又在转账 3 亿给A(T2),不管 T1 和T2谁先执行完毕,最终结果必须是 A 账户增加 2 亿,而不是 3 亿,B增加 1 亿,C减少 3 亿。
(4)持久性(Durability): 一旦事务提交,不管发生什么(崩溃或者出错),数据要保存在数据库中。
确保如果 T1 刚刚提交,数据库就发生崩溃,T1执行的结果依然会保持在数据库中。
因此,如果几个互不知晓的事务在同时修改同一份数据,那么很容易出现后完成的事务覆盖了前面的事务的结果,导致不一致。 事务在最终提交之前都有可能会回滚,撤销所有修改:
如果 T1 事务修改了 A 账户的数据,这时 T2 事务读到了更新后的 A 账户数据,并进行下一步操作,但此时 T1 事务却回滚了,撤销了对 A 账户的修改,那么 T2 读取到的 A 账户数据就是非法的,这会导致数据不一致。
这些问题都是事务需要避免的。
2. Redis中的事务
- MULTI标记一个事务块的开始,事务内的多条命令会按照先后顺序被放进一个队列中,最后由 EXEC 的原子性命令执行
- EXEC执行事务块内的命令
- DISCARD 取消事务,放弃执行事务块内的所有命令
3. 错误处理
语法错误:比如开启事务,第一条命令加入队列,后两条命令为不存在或命名参数个数不对,首先会报错,在执行 EXEC 命令时,则直接返回错误,第一条正确的命令也不会执行。
运行错误:开启事务后使用的一种数据结构的命令来操作另一种数据结构的key(如使用 SADD 操作字符串key),那么依旧会加入到队列中,直到 EXEC 执行时才会返回错误,其他命令正确则正常执行。
4. WATCH命令
假设有两个人A,B共用一个消费账户,该账户有 100 元,首先 A 在超市开启了一个事务,买了 30 元的东西,B在另一个超市直接消费 100 元并先结账,此时账户为 0 元,然后 A 结账时发现账户变为了负数,为了解决这种问题,redis提供了 WATCH 命令。
WATCH定义:监视一个或多个key,如果在事务执行前这个 key 被其他命令所改动,那么事务将被打断。
在 WATCH 命令之后执行 EXEC 或DISCARD后,WATCH命令将会被自动取消,如果想手动取消使用 UNWATCH 即可。
八、持久化(persistence)
由于 redis 性能好得益于将数据存储在内存中,一旦发生宕机数据便会丢失,为此我们需要进行数据的持久化,也就是将数据从内存中同步到硬盘中,使得 redis 重新启动后可以从硬盘中恢复数据。
1. RDB(Redis Database)持久化
根据指定的规则定时将内存中的数据存储到硬盘中, 在重启之后读取硬盘中**.rdb**快照文件将数据恢复到内存中,在redis.conf文件中已存在默认配置。
快照条件:当时间 M 内被改动的键的个数大于 N 时,符合快照条件,比如
save 900 1代表没 900s 至少有 1 个键被改动了则写入快照。dbfilename dump.rdb配置快照文件名称,dir path配置快照保存目录
2. AOF(Append Only File)持久化
AOF持久化记录服务器执行的所有写操作命令形成**.aof**日志文件保存到硬盘中,并在服务器启动时,通过重新执行这些命令来还原数据集。
默认情况下,Redis并没有开启 AOF 持久化,可以通过appendonly yes开启。
AOF有三种同步策略:
- appendfsync always 每一次发送数据变化都会被立刻同步到磁盘中,效率较低但安全性更高
- appendfsync everysec 每秒同步,异步完成,同步效率高,缺点时发生宕机这一秒内操作的数据将会丢失
- appendfsync no 不开启